Autores: Leonardo Leite e Eduardo Hideo Kuroda
 O Radar Parlamentar mostra a conjuntura de uma casa legislativa considerando um certo conjunto de votações realizadas nessa casa. Uma das principais maneiras de selecionar esse conjunto de votações é determinar o período. Exemplo: quero analisar o posicionamento dos parlamentares considerando o ano de 2014. Outra abordagem complementar é por tema: quando o assunto é "meio ambiente", por exemplo, será que as proximidades entre parlamentares se alteram muito em relação ao quadro original que considera todas as votações do período? Para possibilitar tal análise, o Radar possui uma funcionalidade de filtro de palavras-chaves. O usuário pode entrar com palavras como “ambiente, verde” e ver o que acontece.
O Radar Parlamentar mostra a conjuntura de uma casa legislativa considerando um certo conjunto de votações realizadas nessa casa. Uma das principais maneiras de selecionar esse conjunto de votações é determinar o período. Exemplo: quero analisar o posicionamento dos parlamentares considerando o ano de 2014. Outra abordagem complementar é por tema: quando o assunto é "meio ambiente", por exemplo, será que as proximidades entre parlamentares se alteram muito em relação ao quadro original que considera todas as votações do período? Para possibilitar tal análise, o Radar possui uma funcionalidade de filtro de palavras-chaves. O usuário pode entrar com palavras como “ambiente, verde” e ver o que acontece.
Para implementarmos tal funcionalidade no Radar precisamos fazer uso de um mecanismo de busca, que é um sistema desenvolvido para busca de informações. Esse sistema pode ser simples como uma consulta ao banco de dados, como também ser complexo como o Google e o Yahoo. O Radar começou utilizando um mecanismo bem simples, por meio de consultas diretas ao banco de dados. Essa estratégia permitia alguns resultados, mas com várias limitações. Exemplo: ao buscar “EaD” para pesquisar sobre ensino a distância, as votações contendo a palavra “vereador” eram retornadas! E não é tão simples considerar somente as palavras inteiras, pois elas podem ocorrer no começo ou fim de frases e períodos.

Em Software Livre, existem dois sistemas bem conhecidos voltados especificamente para a realização de buscas. São eles o Elasticsearch e o Solr. No Radar, adotamos o Elasticsearch. Tanto o Elasticsearch como o Solr implementam mecanismos avançados de pesquisa como a tokenização e índice invertido de textos. A tokenização faz a quebra de textos longos em palavras e o índice invertido (ou lista invertida) indexa essas palavras associadas ao texto. A busca, então, é feita através das palavras indexadas concedendo o texto associado a ela.
Além desses mecanismos, existem outros que podem melhorar a qualidade da busca, como o stem, que faz a redução de palavras, a remoção de acentos e a remoção de palavras comuns (de, para..). Esses mecanismos estão disponíveis no Elasticsearch, porém é necessário configurá-los, que foi o que fizemos no Radar.
Com o stem, a palavra é reduzida para sua raiz e, através dessa, são buscadas todas suas ramificações. Por exemplo, se o usuário buscar ambientalista, o processo de stem reduzirá ambientalista para ambiental e buscará todas as suas flexões como ambientalistas, ambientais, ambientalismo… Existem duas opções para essa redução: algoritmo ou dicionário. O algoritmo define um conjunto de regras para reduzir qualquer palavra. No dicionário, a redução é feita fazendo a busca da palavra em um dicionário. Comparando as duas propostas, o dicionário é mais preciso, porém o tempo de buscar uma palavra é considerável. Enquanto isso, no algoritmo, a execução e rápida porém com menos precisão da redução. No Radar, acabamos adotando a estratégia de dicionário.
A remoção de acentos faz a conversão de palavras com acento para palavras sem acento na indexação dessa palavra. E por fim, a remoção de palavras comuns não indexa palavras usadas com frequência da gramática brasileira, como “de” e “para”.
Se estiver interessado nos detalhes sobre como configuramos o Elasticsearch no Radar, você pode conferir as instruções de configuração aqui:
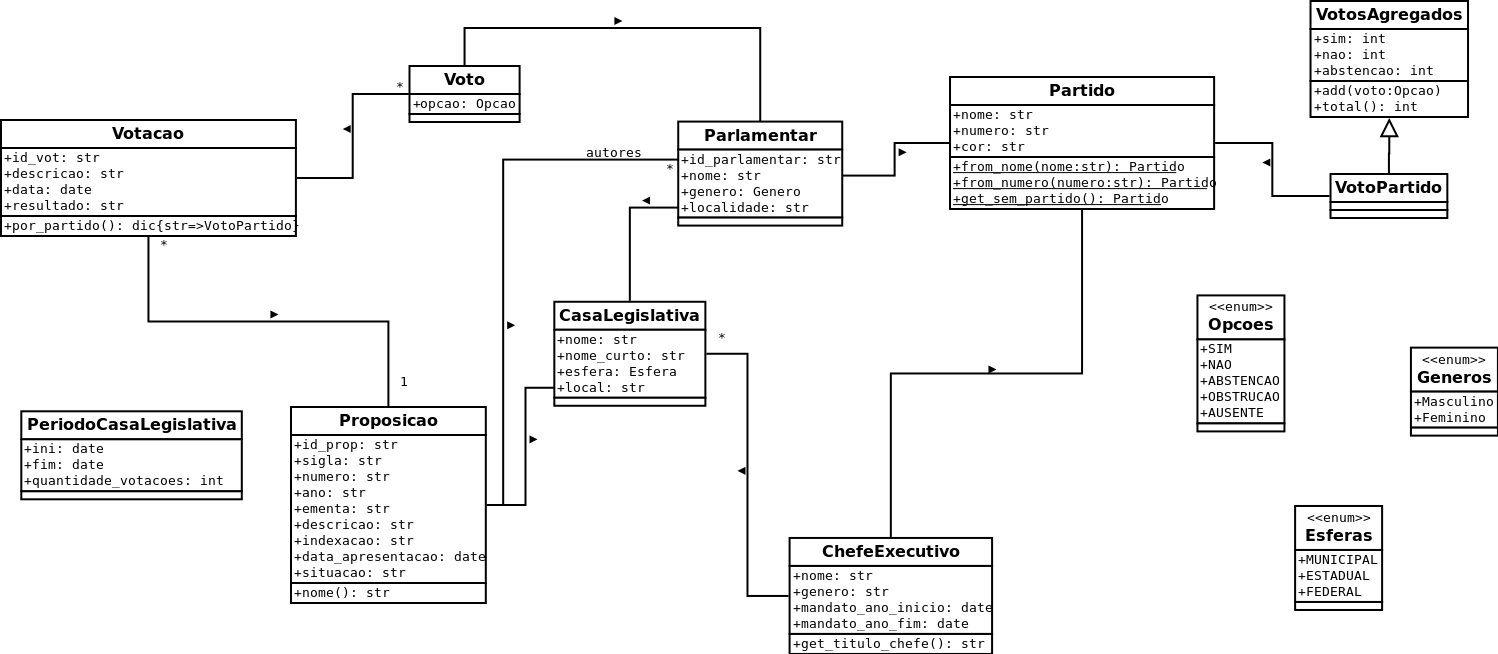
O código do Radar que faz uso do Elasticsearch é esse aqui, o “importador elasticsearch”. O Radar possui uma base de dados relacional (PostgreSQL) com todos os dados que ele precisa para seu funcionamento (o nosso modelo de dados pode ser visto aqui)
O “importador elastic search” copia alguns dados da base relacional para o Elasticsearch. Os dados transferidos são somente aqueles que possuem valor na busca de votações, como títulos, descrições e campos de palavras-chaves.
A estratégia adotada no Radar, de utilizar tanto o PostgreSQL quanto o Elasticsearch, é um exemplo da chamada “persistência poliglota”, que é a ideia de que em uma aplicação podemos utilizar diversos tipos bancos de dados. Cada banco é empregado para a tarefa a qual ele mais se adequa.
O PoliGNU é um grupo formado por estudantes de diversos cursos da Escola Politécnica, bem como de outros cursos da USP, que se dedicam ao desenvolvimento e à divulgação de tecnologia, software e cultura livres, especialmente no que se relaciona à engenharia. O grupo já tem mais de três anos de existência e é aberto à participação de quaisquer interessados(as).
Nosso mailing:
polignu(arroba)googlegroups(ponto)com


Exceto menção em contrário, todo o conteúdo deste site está licenciado sob uma
Licença Creative Commons Atribuição-Compartilhamento pela mesma Licença 3.0 Brasil.
{kind=link}
4 comments
Utilização do ElasticSearch
Enviado por Marcos em dom, 21/02/2016 - 15:39Em primeiro lugar devo parabenizá-los pelo excelente trabalho realizado até o momento. De fato esta é uma iniciativa que impacta diretamente na vida do cidadão brasileiro.
Vou ao ponto central do comentário, gostaria de saber, pontualmente, por quais motivos o ElasticSearch foi escolhido como ferramenta de busca para projeto Radar e quais foram os critérios utilizados na escolha.
Obrigado e mais uma vez parabéns pelo trabalho.
Utilização do ElasticSearch
Enviado por Anônimo em qui, 24/03/2016 - 15:41Olá Marcos
Muito obrigado pelos elogios.
Em relação à escolha do Elasticsearch, o Radar foi iniciado com Postgres e observamos que existia muito esforço de desenvolvimento relação aos requisitos de busca em texto por palavras e seus sinônimos.
Boa parte desse esforço foi porque a arquitetura de SQL não foi focada para buscas de textos.
Então, foi feito um teste com o Elasticsearch já que a ferramenta foi desenvolvida para busca, desde a forma de indexação quando é inserido algum dado até a busca que considera a relevância do resultado.
Os resultados foram bem positivos. O tempo do planejamento até a entrega do mecanismo de busca com um sistema de migração dos dados do Radar que estão no Posgres para o Elasticsearch foi de 3 dias, trabalhando +-6 horas.
Uma outra alternativa de ferramenta de busca seria o Solr que tem a "engine" interna igual a do Elasticsearch, ambos usam Lucene.
[]'s
Eduardo
Olá!
Enviado por leofl em sab, 26/03/2016 - 10:22Olá!
Obrigado pelo comentário!
Resposta curta: essa era a tecnologia que um dos nossos colaboradores, o Eduardo, conhecia bem.
Resposta mais longa: bom, pra pergunta fazer sentido temos que pensar nas alternativas. Como já usamos o Postgres como banco relacional principal, poderíamos pensar pq não fazer tudo no Postgres, o que nos daria uma vantagem em descomplicar a infra do sistema. Antes da gente fazer uso do Elastic Search, eu até já tinha lido um pouco sobre umas funcionalidades de processamento de linguagem natural do Postgres, mas já fazia um tempo. Então não posso responder com propriedade se um é melhor que outro, mas me lembrava de que o eu tinha visto no Postgres era um tanto mais baixo nível do que as funcionalidades que o Eduardo me mostrou (ainda mais considerando umas coisas bem avançadas considerando até o uso de um dicionário de Português). Em virtude do seu comentário, um colega em nossa listou indicou essa possibilidade também: http://www.postgresql.org/docs/9.1/static/textsearch-dictionaries.html, que eu desconhecia até então.
Ou seja, chega alguém no projeto com uma proposta que funciona, as vezes é melhor fazer ela logo do que gastar o mesmo tempo em buscas e comparações com todas as opções possíveis do universo. Ainda mais que no nosso caso, em nosso grupo não tinhamos ninguém com uma expertise maior nessa área de busca textual para propor outras opções. Fica daí talvez uma lição: nessas situações poderíamos usar melhor o facebook do radar pra ampliar o debate pra comunidade sobre outras opções pra um problema.
Mas pra retomar o ponto inicial... em geral mais vale o "show me the code" do que uma longa discussão com uma revisão completa das ferramentas possíveis para a tarefa.
Caráter educacional
Enviado por diraol em sab, 26/03/2016 - 10:55Complementando as respostas do Leonardo e do Eduardo, vale destacar que o Radar também é um espaço de aprendizado com fins educacionais. Desse ponto de vista, podemos, caso alguém tenha interesse, testar outras alternativas e comparar os resultados.
Comentar